 1 mod (p-1)(q-1).
1 mod (p-1)(q-1).
Burt is chief scientist of RSA Laboratories, a division of RSA Data Security, Inc. He received a PhD in computer science from MIT in 1988 and is interested in cryptography and fast-arithmetic techniques. You can contact him burt@rsa.com.
The growing importance of data security, combined with the increased power of PCs, makes cryptography both a practical reality and critical necessity in today's computer systems. But as cryptography becomes more widespread, it touches tools that aren't as powerful as, say, processors like the 80486 or Pentium. For instance, in one recent project, our challenge was to implement 512-bit RSA private-key operations in less than 10 seconds on Zilog's 8-bit Z80180 microcontroller running at 10 million cycles/second.
In this article, I'll share what we've learned about implementing mathematically-intensive systems like RSA on the Z80180.
Zilog's Z80180 (and its counterpart, Hitachi's 64180) is an 8-bit embedded controller that's commonly used in fax machines, modems, printers, and similar applications. It extends the old Z80 processor with a multiply instruction (critical to RSA performance), extra test and I/O instructions, and a "sleep" mode. An internal memory management unit (MMU) maps 16-bit logical addresses to 20-bit physical addresses.
The Z80180, which has a 1-Mbyte address space, has seven 8-bit registers A-E, H, and L, and two index registers, IX and IY. Most arithmetic and logical operations are performed with register A as an accumulator. The 16-bit register pair HL is an accumulator for several 16-bit arithmetic operations, with register pairs BC and DE as operands. The index registers also can accumulate a 16-bit addition.
A multiply instruction multiplies a register pair, overwriting the pair with the 16-bit product. Addressing modes include immediate, direct, register indirect, and indexed based on IX and IY, among others. The usual branch instructions are supported. A special instruction decrements register B, branching if, and only if, the result is nonzero.
Z80180 parts are available that run at 10 million cycles/second; a static version runs at up to 18 million cycles/second. In short, the Z80180 balances performance, cost, and power.
RSA cryptography is based on repeated multiplication, or exponentiation, modulo the product n of two large prime numbers p and q. Each user has two keys, a public key and a private key, and each user's modulus n is different. Users publish the public key, and keep the private key private.
The public key consists of the modulus and a public exponent e. The private key consists of the modulus and a private exponent d. The exponents are related by the equations ed1 mod (p-1)(q-1).
Either key can encrypt or decrypt. For instance, Alice can encrypt a message m for Bob with Bob's public key (nB,eB) by computing c=meb mod nB. Bob recovers the message from the ciphertext c with his private key(nB,dB) by computing m=cdb mod nB. Alice can also encrypt a message with her private key, so that anyone can recover the message with Alice's public key. Only Alice knows the private key, so if the recovered message makes any sense, it must be from Alice; the encrypted message is effectively her "digital signature."
Without the private key, decrypting ciphertext or "signing" a message is generally believed to be as hard as factoring the modulus n into p and q. Factoring, even for modest-sized RSA integers n (say, 512 to 1024 bits), is generally considered a difficult problem. For further information on public-key cryptography and RSA, see "Untangling Public-key Cryptography" by Bruce Schneier (DDJ, May 1992), and my article "Multiple-precision Arithmetic in C" (DDJ, August 1992).
How much work is involved in computing a modular exponentiation of the form a=bc mod d?
The number of modular multiplications to compute bc mod d is at most c-1, and it can be much less. Although no method is known for computing the optimal sequence of multiplications for an arbitrary exponent c--that's an NP-complete problem--heuristic methods get pretty good results.
The "binary" method takes 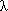 (c)+
(c)+ (c) modular multiplications (see Knuth's The Art of Computer Programming, Volume 2), where (c) is one less than the length of the binary representation of c, and (c) is the number of 1-bits in the binary representation. The method squares for each bit of the exponent except the first, and multiplies for each 1-bit. Let <c(c),...,c0> the bits of c from most to least significant. This algorithm is shown in Figure 1.
(c) modular multiplications (see Knuth's The Art of Computer Programming, Volume 2), where (c) is one less than the length of the binary representation of c, and (c) is the number of 1-bits in the binary representation. The method squares for each bit of the exponent except the first, and multiplies for each 1-bit. Let <c(c),...,c0> the bits of c from most to least significant. This algorithm is shown in Figure 1.
This is pretty good, since no method can do better than log2c on average. The "quaternary" method, which considers the exponent c as radix-4 digits, averages about 1.375(c) modular multiplications; radix-m for larger m may do better. Exponent "recoding" may also help (refer to C.K. Koc's "High-radix and Bit Recoding Techniques for Modular Exponentiation," International Journal of Computer Mathematics, 1987).
The "Chinese Remainder Theorem" (CRT) approach speeds up RSA private-key exponentiation by almost a factor of four by taking advantage of simpler operations modulo the prime factors p and q. Instead of a 512-bit modular exponentiation, we have two 256-bit modular exponentiations, each of which is eight times faster with conventional methods than a 512-bit modular exponentiation.
With CRT and quaternary, a 512-bit RSA private-key operation takes on average about 2x1.375x256=704 256-bit modular multiplications, plus a small overhead due to the CRT. Let's call this 750 256-bit modular multiplications, just to be safe.
Since our operands are several hundred bits long, we'll represent them as multiple-precision arrays. Let r be the digit radix of the machine, so r=256 for the 8-bit Z80180. (Our discussion carries over to any digit radix.) We represent an integer x as an n-digit array x[0],_,x[n-1], according to the sum in Figure 2. Thus x[0] is the least significant digit and x[n-1] is the most significant.
We wish to compute a=bc, where a has 2n digits, and b and c have n digits. An easy algebraic exercise gives the expression in Figure 3(a). Such an expression leads to multiplication by "operand scanning," along the lines of the grade-school approach. We multiply by digits of the operand b from least to most significant, following the weights ri.
A somewhat more difficult exercise gives a different expression as shown in Figure 3(b) which leads to multiplication by "product scanning," which is like convolution in signal processing. We compute digits of the product a from least to most significant, following the weights rk.
If you're unfamiliar with product scanning, see Figure 4 in which the multiplication tableau consists of cross products between pairs of operand digits. Their columnwise sum, with carry propagation right to left, gives the product.
The operand-scanning method computes the product by accumulating partial products [i]ri for each i. As Figure 5 illustrates, there are n iterations. The variable x carries between iterations of the j loop. There is no carry between iterations of the i loop.
Most of the work in this method is in the j loop, so we can estimate the performance by implementing that loop; see Figure 6. Each iteration computes x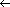 x + a
x + a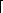 i+j
i+j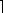 + b[i],c[j]x mod r, and x
+ b[i],c[j]x mod r, and x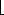 x/r
x/r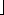 , where j varies. Register C contains the digit b[i], index register IX points to c[j], and index register IY points to a[i+j]. Register B counts down the number of iterations. Register E carries the low half of x from one iteration to the next, and register D contains the value 0. An iteration takes 105 cycles.
, where j varies. Register C contains the digit b[i], index register IX points to c[j], and index register IY points to a[i+j]. Register B counts down the number of iterations. Register E carries the low half of x from one iteration to the next, and register D contains the value 0. An iteration takes 105 cycles.
By hardcoding j as an index to the LD instructions, we can unroll the loop and avoid the last three instructions. The result takes 82 cycles.
It's easy to see that there are n2 iterations of the j loop, so multiplication with this method takes about 82n2 cycles, plus whatever overhead there is in the n iterations of the i loop.
Product-scanning, on the other hand, computes the product by accumulating partial products for each k. (See Figure 7.) As Figure 8 shows, there are 2n iterations. The variable x accumulates within an iteration of the i loop, and between iterations of the k loop. Its value is always less than nr2. If n r then x needs at most three digits.
r then x needs at most three digits.
The index k-i, like i, is always between 0 and n-1. On the last iteration of the k loop, i ranges from n to n-1, so the i loop has no iterations.
The implementation of this method's i loop (Figure 9) takes 79 cycles per iteration. Each iteration computes x�x+b[i]c[k-i], where i varies. Register C contains the value 0, index register IX points to b[i], and index register IY points to c[k-i]. Register B counts down the number of iterations. Registers A, H, and L carry the value of x from one iteration to the next. (You can save a few more cycles by exchanging the roles of HL and IY. LD E,(HL) costs only six cycles and INC HL only four, while ADD IY,DE costs ten, for a net savings of eight cycles. But "shifting" IY after the i loop is a little harder. Also, the Z80180 doesn't have an indexed addressing mode for HL. If we're going to unroll the loop, we're best staying with IY as an index register.)
This method is simpler than the operand-scanning method on the Z80180, and it's also 25 percent faster per iteration!
Unrolling, as expected, saves 23 cycles; we hardcode i as an index to the LD instructions. The result takes just 56 cycles per iteration.
Multiplication with this method takes about 56n2 cycles, plus whatever overhead there is in the 2n iterations of the k loop. Although there are more iterations of the k loop here than iterations of the i loop in the operand-scanning method, the additional overhead is not significant compared to the 26n2-cycle savings.
We have our first estimate of RSA performance: 256-bit multiplication, with n=32 and 10 percent overhead, takes 56x322x1.1 (about 63,000) cycles, or 6.3 milliseconds at 10 million cycles/second.
Why (and when) is product scanning faster than operand scanning? Product scanning stores each product digit once, not after every multiply. Of course, it fetches operand digits before every multiply. But it doesn't fetch product digits at all! In all, product scanning has about one-third fewer memory references than operand scanning. It also has many fewer "shifts."
Product scanning needs more register storage than register scanning. The variable x in product scanning needs at least three digits, whereas in the operand-scanning method it needs only one digit. With two pointers, two multiplier inputs, and perhaps a counter already in registers, some processors may not have enough register storage left. The Z80180 does have enough left, a benefit of its 16-bit register pairs. (Other processors may have enough registers for an r=256 implementation, but not an r=216 implementation; operand scanning with r=216, if possible, would be preferable to product scanning with r=256.)
BigMult is a subroutine that computes the product of two multiple-precision integers. Listing One (page 90) gives a non-optimized C version, Listing Two (page 90) is its header file, and Listing Three (page 90) is an optimized assembly-language version in Z80180 assembler (written with Microtec Research's Z80180 Assembler 6.0. It interfaces to Microtec's C 6.0.) In each version, global variables BIG_MULT_A, BIG_MULT_B, BIG_MULT_C, and BIG_MULT_N correspond to variables a, b, c, and n discussed earlier. BigMult implements product-scanning, and consists of two parts--one for k from 0 to n-1, the other for k from n to 2n-1. Each part calls an "inner loop" that computes the sum in Figure 7. (This is the same as the i loop in Figure 9.) For performance, the inner loop is unrolled, and that's where efficient RSA methods give way to Z80180 programming techniques.
The unrolled inner loop presents a challenge because we have to jump to a different point in the loop each time--the number of iterations varies from 0 to n-1. We must therefore jump to an indirect address. The only way to do this seems to be to jump indirectly through one of the registers HL, IX, or IY. But each of them already has a role in the unrolled loop.
The solution is a familiar one in Z80180 programming: Don't jump to the loop, return to it. The sequence:
LD DE,(address) PUSH DE RET
loads an address into register pair DE, pushes it onto the stack, and returns, thereby jumping to the address.
Since the inner loop is called from more than one place, the caller pushes the return address on the stack before pushing the inner loop address. The inner loop then returns to the right caller.
Index registers IX and IY point to operands b and c, respectively. During the first half, IX moves ahead while IY stays fixed; during the second half, IY moves ahead while IX stays fixed. The jump address changes each time by the length of the inner iteration, so we just add or subtract that length before jumping. The pointer to the product a is on the stack.
The REPT directive unrolls the inner loop, with the variable iteration ranging from the number of iterations down to 1. The inner iteration hardcodes the counter as an index to the load instructions that fetch b[i] and c[j].
BigMult can handle up to 128-byte numbers, being limited by the range of offsets in the indexed load instruction. With a slight variation to the outer loop, BigMult could handle larger numbers.
Multiplication is half of modular multiplication; the other half is division. Division takes only a little longer than multiplication, though implementing it is generally more difficult.
An alternative is Montgomery multiplication which has the advantage in that it can be implemented either by product or operand scanning--and its implementation is almost identical to multiplication. Division seems inherently to involve operand scanning, and we prefer product scanning for the Z80180. (See the accompanying textbox "Montgomery Multiplication.")
A disadvantage of Montgomery multiplication is that you need to convert in and out of the Montgomery "representation." But once you're in that representation, Montgomery multiplication keeps you there. You need only to convert at the start of modular exponentiation, and convert out at the end.
Montgomery multiplication code takes just about twice as many cycles as ordinary multiplication, which brings us to around 12.6 milliseconds for 256-bit Montgomery multiplication.
It takes 750 times as long, or approximately 9.5 seconds, for a 512-bit RSA private-key operation--comfortably within our 10-second goal.
Architectural features such as the Z80180's 16-bit HL register-pair open the door to efficient methods such as multiplication by product scanning. Programming techniques such as jumping with a return instruction also play an important role.
Further work we're considering includes special code for modular squaring which is 25 percent faster than modular multiplication. Since most of the estimated 750 modular multiplications are squarings, we can expect to save perhaps another two seconds.
Many of the methods and techniques can be extended to other processors, and the area of cryptography implementation remains a critical and practical challenge.
Zilog's Mark van Zanten, Alan Chan, and Adam Tucholski provided computing support for the code described in this article. RSA's Jim Bidzos encouraged me to publish the article, and RSA's Matt Robshaw offered comments and suggestions.
Most methods for modular multiplication involved division or an approximation to it until Montgomery published a brief note in 1985 renewing earlier ideas of Hensel (see "Modular Multiplication without Trial Division" by P.L. Montgomery, Mathematics of Computation, 1985).
Let d be an odd integer, n be its length in digits, and r be the digit radix. Let v be the least positive integer such that vd+1 is divisible by rn. This value depends only on d, r and n, and can be computed by the extended Euclidean algorithm (see Knuth).
Montgomery multiplication, which we write Md, is defined as Md(b,c)=
(bc+(vbc mod rn)d)/rn, and it has the following properties:
The first k loop computes in a the equivalent of vbc mod rn, and adds the (vbc mod rn)d term and the bc term. Since the least significant digits of the sum are known to be 0, the loop does not store them, although it does carry between iterations in the variable x.
The second k loop continues to add the (vbc mod rn)d and bc terms, storing the sum in a. By starting at a[0] rather than a[n], the loop divides by rn in the process.
The interleaved product-scanning approach saves loop overhead, and it needs only n digits for a, not 2n digits as in multiplication followed by division, or in a noninterleaved approach.
--B.S.K.
Cycles Instruction
LOOP:
; Fetch c[j] and multiply by b[i].
; HL contains the 16-bit product.
14 LD H,(IX)
4 LD L,C
17 MLT HL
; Add carry to HL.
7 ADD HL,DE
; Fetch a[i+j], and add to HL.
14 LD E,(IY)
7 ADD HL,DE
; Store new a[i+j] and copy new carry.
15 LD (IY),L
4 LD E,H
; Next iteration.
7 INC IX
7 INC IY
9 DJNZ LOOP
---
105
========================================================================
Cycles Instruction
========================================================================
LOOP:
; Fetch b[i] and c[k-i], and multiply.
; DE contains the 16-bit product.
14 LD D,(IX)
14 LD E,(IY)
17 MLT DE
; Add product to AHL.
7 ADD HL,DE
4 ADC A,C
; Next iteration.
7 INC IX
7 DEC IY
9 DJNZ LOOP
--
79
========================================================================
_THE Z80180 AND BIG-NUMBER ARITHMETIC_
by Burton Kaliski, Jr.
[LISTING ONE]
/* Copyright (C) RSA Data Security, Inc. created 1993. All rights reserved. */
#include "bigmult.h"
unsigned char BIG_MULT_A[256];
unsigned char BIG_MULT_B[128];
unsigned char BIG_MULT_C[128];
unsigned int BIG_MULT_N;
/* Computes a = b*c. Lengths: a[2*n], b[n], c[n]. */
void BigMult (void)
{
unsigned long x;
unsigned int i, k;
x = 0;
for (k = 0; k < BIG_MULT_N; k++) {
for (i = 0; i <= k; i++)
x += ((unsigned long)BIG_MULT_B[i])*BIG_MULT_C[k-i];
BIG_MULT_A[k] = (unsigned char)x;
x >>= 8;
}
for (; k < (unsigned int)2*BIG_MULT_N; k++) {
for (i = k-BIG_MULT_N+1; i < BIG_MULT_N; i++)
x += ((unsigned long)BIG_MULT_B[i])*BIG_MULT_C[k-i];
BIG_MULT_A[k] = (unsigned char)x;
x >>= 8;
}
}
[LISTING TWO]/* Copyright (C) RSA Data Security, Inc. created 1993. All rights reserved. */ extern unsigned char BIG_MULT_A[256]; extern unsigned char BIG_MULT_B[128]; extern unsigned char BIG_MULT_C[128]; extern unsigned int BIG_MULT_N; void BigMult (void);[LISTING THREE]
; Copyright (C) RSA Data Security, Inc. created 1993. All rights reserved.
NAME BIGMULT
SEGMENT DSEG,BYTE,DATA
PUBLIC _BIG_MULT_A
_BIG_MULT_A DEFS 256
PUBLIC _BIG_MULT_B
_BIG_MULT_B DEFS 128
PUBLIC _BIG_MULT_C
_BIG_MULT_C DEFS 128
PUBLIC _BIG_MULT_N
_BIG_MULT_N DEFS 2
address DEFS 2
SEGMENT CSEG,BYTE,CODE
; BigMult computes a = bc.
; Assumes 1 <= n <= 128.
; Lengths: a[2*n], b[n], c[n].
PUBLIC _BigMult
_BigMult:
; Save registers.
PUSH IX
; Point address to end of inner loop.
LD HL,endInnerLoop
LD (address),HL
; Push pointer to a.
LD IX,_BIG_MULT_A
PUSH IX
; Set x <- 0, point IX to b[0], and point IY to c[0]. HL is x.
; C = 0 is a constant.
LD HL,0
LD IX,_BIG_MULT_B
LD IY,_BIG_MULT_C
LD C,0
; n iterations.
LD A,(_BIG_MULT_N)
LD B,A
firstLoop:
; Clear carry and call inner loop. The call is implemented with a "return"
; since there aren't enough registers to hold the address. The inner loop
; computes the inner iteration for (i,j) from (0,k) to (k-1,1).
LD DE,firstLoopReturn
PUSH DE
LD DE,(address)
PUSH DE
XOR A
RET
firstLoopReturn:
; Compute x <- x + b[k]*c[0].
LD D,(IX)
LD E,(IY)
MLT DE
ADD HL,DE
ADC A,C
; Compute a[k] <- x mod r, and increment k.
EX (SP),IX
LD (IX),L
INC IX
EX (SP),IX
; Compute x <- x / r, where r is the digit radix.
LD L,H
LD H,A
; Move IX forward, move address back, decrement loop counter, and repeat.
INC IX
PUSH HL
LD HL,(address)
LD DE,-innerIterationLen
ADD HL,DE
LD (address),HL
POP HL
DJNZ firstLoop
; Move address forward. (Number of inner iterations should be the same the
; last time through the first loop as first time through second loop: n-1.)
PUSH HL
LD HL,(address)
LD DE,innerIterationLen
ADD HL,DE
LD (address),HL
POP HL
; n iterations.
LD A,(_BIG_MULT_N)
LD B,A
secondLoop:
; Clear carry and call inner loop. The call is implemented with a "return"
; since there aren't enough registers to hold the address. The inner loop
; computes the inner iteration for (i,j) from (k-n+1,n-1) to (n-1,k-n+1).
LD DE,secondLoopReturn
PUSH DE
LD DE,(address)
PUSH DE
XOR A
RET
secondLoopReturn:
; Compute a[k] <- x mod r, and increment k.
EX (SP),IX
LD (IX),L
INC IX
EX (SP),IX
; Compute x <- x / r.
LD L,H
LD H,A
; Move IY forward, move address forward, decrement loop counter, repeat.
INC IY
PUSH HL
LD HL,(address)
LD DE,innerIterationLen
ADD HL,DE
LD (address),HL
POP HL
DJNZ secondLoop
; Pop pointer to a.
POP IX
; Restore registers and return.
POP IX
RET
; Unrolled inner loop. Each iteration computes x <- x + b[i]c[j] for some
; (i,j). HL is x, A is carry, IX points to b[last i], IY points to c[last j].
InnerLoop:
iteration DEFL 127
REPT 127
LD D,(IX-iteration)
LD E,(IY+iteration)
MLT DE
ADD HL,DE
ADC A,C
iteration DEFL iteration-1
ENDR
endInnerLoop:
RET
innerLoopLen EQU endInnerLoop - InnerLoop
innerIterationLen EQU innerLoopLen / 127
END
Copyright © 1993, Dr. Dobb's Journal