PowerPC 601 and Alpha 21064
Second generation RISC processors
Shlomo Weiss and James E. Smith
Shlomo is a faculty member in the Department of Electrical Engineering/Systems at Tel Aviv University. Jim is a faculty member in the Department of Electrical and Computer Engineering at the University of Wisconsin-Madison. They are the authors of POWER and PowerPC: Principles, Architecture, Implementation (Morgan Kaufmann Publishers, 1994). Shlomo and Jim can be reached through the DDJ offices.
Just as there is more than one way to skin a cat, there is more than one way to implement RISC concepts. The PowerPC is a good example of a high-performance RISC implementation that is tuned to a specific architecture. It isn't, however, the only RISC implementation style that processor designers have used. We'll compare the PowerPC 601 to an alternative RISC architecture and implementation--the DEC Alpha 21064.
The 601 focuses on relatively powerful instructions and great flexibility in instruction processing. The 21064 depends on a very fast clock, with simpler instructions and a rigid implementation structure. Both the 601 and the 21064 have load/store architectures with 32-bit, fixed-length instructions. Each has 32 integer and 32 floating-point registers, but beyond these basic properties, they have little in common; see Table 1.
The 601 has a relatively small die size due to IBM's aggressive 0.6-micron CMOS technology with four levels of metal (a fifth metal layer is used for local interconnect); see Table 2. The cache size of each chip largely accounts for the substantial difference in the transistor count. Two striking differences appear in clock cycle and power dissipation. The 21064 is much faster, but also runs much hotter. It's well-known that CMOS's faster clock gives it more power, but even if a fast clock "wins" in performance, its higher power-consumption requirements could "lose" in usefulness--in portable PCs, for example.
All instructions for the 601 are processed in the fetch and dispatch stages. Branch and Condition Register instructions go no farther. Fixed-point and load/store instructions are also decoded in the dispatch stage of the pipe and are then passed to the FXU to be processed. Most fixed-point arithmetic and logical instructions take just two clock cycles in the FXU: one to execute and one to be written into the register file. All load/store instructions have three cycles in the FXU: address generation, cache access, and register write. This assumes a cache hit, of course.
The 601 design emphasizes getting the FXU instructions processed in as few pipeline stages as possible. This low-latency design is evident in the combining of the dispatch and decode phases of instruction processing. The effect of an instruction pipeline's length on performance is most evident after a branch, when the pipeline may be empty or partially empty.
The shorter the pipeline, the more quickly instruction execution can start again. Most of the time, the first instructions following a branch are FXU instructions (even in floating-point-intensive code), because a program sequence following a branch typically begins by loading data from memory (or by preparing addresses with fixed-point instructions). Obviously, a short FXU pipeline is desirable.
In contrast, floating-point instructions are processed more slowly. FPU decoding is not performed in the same clock cycle as dispatching. The first floating-point instruction following a branch is likely to depend on a preceding load, so the extra delay in the floating-point pipeline will not affect overall performance significantly. This extra delay reduces the interlock between a floating load and a subsequent dependent floating-point instruction to just one clock cycle.
The buffer at the beginning of the FPU can hold up to two instructions; the second buffer slot is the decode latch, where instructions are decoded. In the FXU pipeline, there is a one-instruction decode buffer that can be bypassed. The decode buffers provide a place for instructions to be held if one of the pipelines blocks due to some interlock condition or an instruction that consumes the execute stages for multiple cycles. By getting instructions into the decode buffers when a pipeline is blocked, the instruction buffers are allowed to continue dispatching instructions (especially branches) to nonblocked units.
The 21064 pipeline complex is composed of three parallel pipelines: fixed-point, floating-point, and load/store. The pipelines are relatively deep, and the integer and load/store pipes are the same length. These are the stages that an instruction may go through:
- F, Fetch. The instruction cache is accessed, and two instructions are fetched.
- S, Swap. The two instructions are directed to either the integer or the floating-point pipeline, sometimes swapping their positions, and branch instructions are predicted.
- D, Decode. Instructions are decoded in preparation for issue--the opcode is inspected to determine the register and resource requirements of each instruction. Unlike IBM processors, registers are not read during the decode stage.
- I, Issue. Instructions are issued and operands are read from the registers. The register and resource dependencies determine if the instruction should begin execution or be held back. After the issue stage, instructions are no longer blocked in the pipelines, and can therefore be completed.
- A, ALU stage 1. Integer adds, logicals, and short-length shifts are executed. Their results can be immediately bypassed back, so these appear to be single-cycle instructions. Longer-length shifts are initiated in this stage, and loads and stores do their effective-address add.
- B, ALU stage 2. Longer-length shifts complete and their results are bypassed back to ALU 1, so these are two-cycle instructions. For loads and stores, the data cache tags are read. Loads also read cache data.
- W, Write stage. Results are written into the register file. Cache hit/miss is determined. Data from store instructions that hit is stored in a buffer. It will then be written into the cache during a cycle with no loads.
The 21064 integer pipeline relies on a large number of bypasses to achieve high performance. In a deep pipeline, bypasses reduce apparent latencies. There are a total of 38 separate bypass paths.
Floating-point instructions pass through F, S, D, and I stages just like integer instructions. Floating-point multiply and add instructions are performed in stages F through K. The floating-point divide takes 31 cycles for single precision and 61 cycles for double precision.
The dispatch rules in the 601 are quite simple. The architecture has three units--Integer (or Fixed Point), Floating Point, and Branch--that can process instructions simultaneously. Integer operate instructions and all loads and stores go to the same pipeline (FXU), and only one instruction of this category may issue per clock cycle.
The 21064's swap corresponds to the 601's dispatch. Instructions issue two stages later. In the 21064, instructions must issue in their original program order, and dispatch (that is, the swap stage) helps to enforce this order. A pair of instructions belonging to the same aligned doubleword (or "quadword" in DEC parlance)can issue simultaneously. Consecutive instructions in different doublewords may not dual-issue, and if two instructions in the same doubleword cannot issue simultaneously, the first in the program sequence must issue first.
The 21064 implements separate integer and load/store pipelines, and several combinations of these instructions may be dual-issued (with the exception of integer operate/floating store, and floating operate/integer store). The separate load/store unit requires an extra set of ports to both the integer and floating register files. The load/store ports are shared with the Branch Unit, which has access to all the registers because the 21064 architecture has no condition codes, and branches may depend on any integer or floating register. Consequently, branches may not be issued simultaneously with load or store instructions.
Table 3 summarizes the dispatch rules for both chips. In the 601 table, an X in the corresponding row/column indicates that two instructions may simultaneously issue. For three instructions, all three pairs must have Xs. In the 21064 table, two instructions with an X may simultaneously issue.
The ability of the 21064 to dual-issue a load with an integer-operate instruction is a definite advantage over the 601. Many applications (not to mention the operating system) use very little floating point; the 21064 can execute these apps with high efficiency, but the 601 can execute only one integer instruction per clock cycle (while its FPU sits idle).
The 21064 and 601 have register files with almost the same number of ports; see Table 4. Both start with one write and two read ports to service operate instructions. The 21064 provides an additional pair of read/write ports for load/store unit data. Branches share the load/store register ports, which brings the count up to 3R/2W for both integer and floating-register files. One additional integer read port is needed to get the address value for stores and loads. Doing an integer store in parallel with an integer operate involves an extra integer read port, but not allowing a register-plus-register addressing mode saves a register-read port.
The 601's one write and two read ports for operate instructions are fortified by an additional integer read port for single-cycle processing of store with index instructions, which read three registers (two for the effective address, one for the result). An extra integer write port allows the result of an operate instruction and data returned from the cache to be written in the same clock cycle. The same consideration accounts for two write ports in the floating-register file. The three floating-point read ports accommodate the combined floating multiply/add instruction.
The 21064 uses separate instruction and data caches. The data caches are small, (8KB) direct-mapped data caches designed for very fast access times; see Figure 1(a). The address add consumes one clock cycle. During the next clock cycle, the Translation Lookaside Buffer (TLB) is accessed and the cache data and tag are read. In a direct-mapped cache this is easy because only one tag must be read, and the data, if present, can only be in one place. The TLB address translation completes in the third cycle, and the tag is compared with the upper address bits. A cache hit or miss is determined about halfway through this clock cycle. The data are always delivered to the registers as an aligned, 8-byte doubleword. Alignment, byte selecting, and the like must be done with separate instructions.
In the 601, the unified data/instruction cache is much larger--32 KB--and is 8-way set associative, yielding a higher hit rate than the 21064. Figure 1(b), shows how much more "work" the 601 does in a clock cycle. It does an address add and the cache directory/TLB lookup in the same cycle. During the next cycle, it accesses the 32-byte-wide data memory and selects and aligns the data field.
The 601 gets more done in fewer stages, but the 21064's clock cycle is about a third to a fourth the length of the 601's. Consequently, the 601's two clock cycles take much longer than the 21064's three cycles.
Example 1 shows a For loop in C and its corresponding 21064 assembly-language code. Note in this and subsequent examples that the notation, bit numbering and assembly language do not conform to that of Alpha; they have been modified to be consistent with PowerPC notation. Example 2 is the 21064 pipeline flow for the example loop. It shows in-order issue, dual-issue for aligned instruction pairs, and the relatively long six-clock-period floating-point latency. After the I stage, instructions never block.
The importance of the swap stage is clear from the first two instructions, which cannot dual-issue because both are loads. The second instruction is held for one cycle while the first moves ahead. The first dual-issue occurs for the first addq-mult pair. Because mult is the first instruction in the doubleword, addq must wait, even though no dependencies hold it back. The sequence of dependent floating-point instructions paces instruction issue for most of the loop. Note that the floating store issues in anticipation of the floating-point result. It waits only four--not six--clock periods for the result so that it reaches its write stage just in time to have the floating-point result bypassed to it.
A bubble follows the predicted branch at the end of the loop. Because other instructions in the pipeline are blocked, however, by the time the ldt following the branch is ready to issue, the bubble is "squashed." That is, if the instruction ahead of the bubble blocks and the instruction behind proceeds, the bubble is squashed between the two and eliminated.
Overall, the loop takes 16 clock periods per iteration in steady state. (The first ldt passes through I at time 4; during the second iteration, it issues at time 20.) In comparison, the 601 takes six (longer) clock periods.
Floating-point latencies are a major performance problem for the 21064 when it executes this type of code. Also, in-order issue prevents the loops from "telescoping" together as they would in the 601--there is very little overlap among consecutive loop iterations, and the small amount that occurs is mostly due to branch prediction. Each parallelogram in Figure 2 illustrates the general shape of the pipeline flow for a single loop iteration.
In the 601, the branch processor eliminates the need for branch prediction, and the out-of-order dispatch, along with multiple buffers placed at key points, telescopes the loop iterations. Telescoping in the 601 is limited by the lack of store buffer in the FPU, which other implementations may choose to provide. The RS/6000, for example, has register renaming, deeper buffers, and more bypass paths; it achieves much better telescoping than the 601.
Software pipelining or loop unrolling are likely to provide much better performance for a deeply pipelined implementation like the 21064. The DEC compilers unroll loops. Example 3 shows the unrolled version of Example 2. The example loop is unrolled four times. The clock period at which instructions pass through the I stage is shown in the right-hand column. Now, in steady state, four iterations take 23 clock periods (about six per iteration), more than three times better than the rolled version. Unrolling also emphasizes the performance advantage of dual-issue.
Loop unrolling also improves the performance of the 601, as Example 4 shows. After dispatching in the 601, instructions may be held in a buffer or in the decode stage if the pipeline is blocked. Hence, we show FXU and FPU decode time, and BU execute time (which is the same cycle in which a branch is decoded).
Assume that the loop body is aligned in the cache sector. Eight instructions are fetched, and instruction fetching can keep the instruction buffer full until time 2; after that, the cache is busy with load instructions. The instruction queue becomes empty and the pipeline is starved for instructions, but these cannot be fetched until time 9, when the cache finally becomes available. At this time, the six remaining instructions of the cache sector are fetched (the first two were fetched at time 2).
The unrolled loop (four iterations) takes 20 clock cycles (five clock cycles per loop iteration versus six in the rolled version).
There are significant differences in the way the PowerPC and Alpha architectures handle branches; see Figure 5. The PowerPC has a special set of registers designed to implement branches. Conditional branches may test fields in the Condition Code Register and the contents of a special register, the Count Register. A single branch instruction may implement a loop-closing branch whose outcome depends on both the Count Register and a Condition Code value. Comparison instructions set fields of the Condition Code Register explicitly, and most arithmetic and logical instructions may optionally set a condition field by using the record bit.
In the Alpha, conditional branches test a general-purpose register relative to zero or to odd or even. Thus, a test can be performed on the result of any instruction. Comparison instructions leave their result in a general-purpose register.
Certain control-transfer instructions save the updated program counter and use it as a subroutine return address. In the Alpha, these are special jump instructions that save the return address in a general-purpose register. In the PowerPC, this is done in any branch by setting the Link (LK) bit to 1, and saving the return address in the Link Register.
The Alpha also implements a set of conditional move instructions that move a value from one register to another, but only if a condition, similar to the branch condition, is satisfied. These conditional moves eliminate branches in many simple, conditional code sequences; see Example 5. A simple If-Then-Else sequence is given in Example 5(a). A conventional code sequence appears in Example 5(b); the timing shown is for the best-case path, assuming a correct prediction. Example 5(c) uses a conditional move. While the load is being done, both shifts can essentially be performed for free. The shift 4 is tentatively placed in register r3 to be stored to memory. If the test of a is True, then the conditional move to c replaces the value in r3 with the shift 2 results. The total time is shorter than the branch implementation (even in the best case) and does not depend on branch prediction.
In general, branch target addresses are determined in the following ways:
- Adding a displacement to the program counter (PC relative). Available in both architectures.
- Absolute. Available only in the PowerPC, where the displacement is interpreted as an absolute address if the Absolute Address (AA) bit is set to 1.
- Register indirect. Available for instructions not shown in Figure 3. These are the XL-form conditional branches in the PowerPC and jump instructions in the Alpha. General-purpose registers in the Alpha are used, and the Count Register and Link Register are used in the PowerPC.
Both processors predict branches to reduce pipeline bubbles. The 601 uses a static branch prediction made by the compiler. Also, as a hedge against a wrong prediction, the 601 saves the contents of the instruction buffer following a branch-taken prediction until instructions from the taken path are delivered from memory; thus, the instructions on the not-taken path are available immediately if a misprediction is detected.
The 21064 implements dynamic branch prediction with a 2048-entry table; one entry is associated with each instruction in the instruction cache. The prediction table updates as a program runs and contains the outcome of the most recent execution of each branch. This predictor is based on the observation that most branches are decided the same way as on their previous execution. This is especially true for loop-closing branches.
This type of prediction does not always work well for subroutine returns, however. A subroutine may be called from a number of places, so the return jump is not necessarily the same on two consecutive executions. The 21064 has special hardware to predict the target address for return-from-subroutine jumps. The compiler places the lower 16 bits of the return address in a special field of the jump-to-subroutine instruction. When this instruction is executed, the return address is pushed on a four-entry prediction stack, so return addresses can be held for subroutines nested four deep. The stack is popped prior to returning from the subroutine, and the return address is used to prefetch instructions from the cache.
We are now ready to step through the pipeline flow for the Alpha conditional branches; see Figure 4.
The swap stage of the pipeline examines instructions in pairs. After the branch instruction is detected and predicted, it takes one clock cycle to compute the target address and begin fetching, which may lead to a one-cycle bubble in the pipeline. The pipeline is designed to allow squashing of this bubble. In the case of a simultaneous dispatch conflict, as in Figure 4(a), the instruction preceding the branch must be split from it anyway, so the branch instruction waits a cycle and fills in the bubble naturally. If the pipeline stalls ahead of the branch, the bubble can be squashed by having an instruction behind the branch move up in the pipe. If the bubble is squashed and the prediction is correct, the branch effectively becomes a zero-cycle branch.
Figure 4(b) shows the incorrect-prediction case. The branch instruction registers are read during issue stage. During the A stage, the register can be tested and the correctness of the prediction determined quickly enough to notify the instruction-fetch stage if there is a misprediction. Then, the correct path can be fetched in the next cycle. As a result, four stages of the pipeline must be flushed if the prediction is incorrect. For the jump-to-subroutine instruction, the penalty for a misprediction is five cycles.
For branches, the biggest architectural difference between the Alpha and the PowerPC is that the Alpha uses general-purpose registers for testing and subroutine linkage, while the PowerPC uses special-purpose registers held in the Branch Unit. This allows it to execute branch instructions in the Branch Unit immediately after they are fetched. In fact, the PowerPC looks back in the instruction buffer so that it can execute, or at least predict, branches while they are being fetched. The Alpha implementation, in contrast, must treat branch instructions like the other instructions. They are decoded in the D pipeline stage, read registers in I, and executed in the A stage.
Table 5 compares the branch penalties for integer-conditional branches (far more common than floating-point branches). The penalties are expressed as a function of the number of instructions (distance) separating the condition determining instruction (compare) and the branch from the correctness of the prediction. The compare-to-branch instruction count is significant only in the 601, however. Instruction cache hits are assumed.
In the 21064, correctly predicted branches usually take no clock cycles. They take one clock cycle when a bubble created in the swap stage is not later squashed. The 601 has a zero-cycle branch whenever there is enough time to finish the instruction that sets the condition code field prior to the branch and to fetch new instructions. This may take two clock cycles: one to execute the compare instruction, and one to fetch instructions from the branch target. This second clock cycle may be saved when a branch is mispredicted but is resolved before overwriting the instruction buffer; instructions may be dispatched from the buffer right after determining that the branch was not taken. With a two-instruction distance, the 601 has a zero-cycle branch even if it was mispredicted; the 21064 always depends on a prediction, regardless of the distance.
The PowerPC requires fewer branch predictions in the first place; see Table 6. In the 601, all loop-closing branches that use the CTR register do not have to be predicted; in the Alpha these are ordinary conditional branches, although loop-closing branches are easily predictable. A subroutine return must read an integer register in the Alpha, so these branches are predicted via the return stack. The PowerPC can execute return jumps immediately in the Branch Unit; there is no need for prediction.
Table 5 and Table 6 show that accurate branch prediction is much more critical in the 21064. Not only does the 21064 predict more of the branches, the penalties tend to be higher when it is wrong. For this reason, the 21064 has much more hardware dedicated to the task--history bits and the subroutine return stack. The Alpha architecture also reduces the penalty for a misprediction by having branches that always test a register against zero; testing one register against another would likely take an additional clock cycle.
Some doubt the PowerPC method of using special-purpose registers for branches because they present a potential bottleneck. We think not. These registers allow many branches to be executed quickly without prediction and are important for supporting loop telescoping.
The Alpha is a 64-bit-only architecture. The PowerPC has a mode bit, and implementations may come in either 32- or 64-bit versions; the 601 is a 32-bit version. All 64-bit versions must also have a 32-bit mode. The mode determines whether the condition codes are set by 32- or 64-bit operations.
The Alpha defines a flat, or linear, virtual-address space and a virtual address whose length is implementation dependent within a specified range. The PowerPC supports a system-wide, segmented virtual-address space in either 32- or 64-bit mode. Differences between the two modes affect the number of segments and their size, which also results in a difference in the virtual-address space (52 bits versus 80 bits).
Currently, software developers and architects seem to favor flat, virtual-address spaces, although the very large segments available in the PowerPC shouldn't present many problems. The Alpha was defined as a 64-bit architecture from the start, so developers can easily provide a flat virtual-address space. The POWER architecture, however, was defined with 32-bit integer registers that were also used for addressing. This presented the POWER architects with a dilemma: Either use a flat, 32-bit virtual-address space (which would likely be too small in the very near future) or encode a larger address in 32 bits. Such an encoding led to the segmented architecture inherited by the PowerPC. Also, and perhaps more importantly, the single, shared-address space facilitates capability-based memory-protection methods similar to those used in IBM's AS/400 computer systems.
The Alpha architecture specification does not define a page-table format. Because TLB misses are handled by trapping to system software, Alpha systems using different operating systems may have different page-table formats. Two likely alternatives are VAX/VMS and OSF/1 UNIX. A Privileged Architecture Library (PAL) provides an operating-system-specific set of subroutines for memory management, context switching, and interrupts. The Alpha instruction set includes the format in Figure 5 for PAL instructions used to define operating-system primitives.
The Call PAL instructions are like subroutine calls to special blocks of instructions, whose locations are determined by one of five different PAL opcodes. A PAL routine has access to privileged instructions but employs user-mode address translation. While in the PAL routine, interrupts are disabled to assure the atomicity of privileged operations that take multiple instructions. For example, if one instruction turns address mapping off, an interrupt should not occur until another instruction can turn it back on. The details of virtual-address translation and page-table format are a system-software issue to be defined in the context of the particular operating system using PAL functions.
Figure 6 compares the format of memory instructions. The format of instructions using the displacement-addressing mode is identical in the PowerPC and Alpha. The effective address is calculated in the same way in both architectures except for the register with the value 0, which is register 0 in the PowerPC and register 31 in the Alpha. There is no indexed addressing in the Alpha. As previously mentioned, this saves a register read port.
Another Alpha characteristic is that load and store instructions transfer only 32- or 64-bit data between a register and memory; there are no instructions to load or store 8-bit or 16-bit quantities. The Alpha architecture does include a set of instructions to extract and manipulate bytes from registers. This approach simplifies the cache interface so that it does not have to include byte-level shift-and-mask logic in the cache access path.
In Example 7, the core of a strcpy routine moves a sequence of bytes from one area of memory to another; a byte of zeros terminates the string. The ldq is a load-unaligned instruction that ignores the low-order three bits of the address; in the example, it loads a word into r1, addressed by r4. The extract byte (extbl) instruction uses the same address, r4, but only uses the three low-order bits to select one of the eight bytes in r1. The byte is copied into r2. To move the byte to s, the sequence begins with another load unaligned instruction to get the word containing the destination byte. The mask byte (maskbl) instruction uses the three low-order bits of r3 (the address of s) to zero out a byte in the just-loaded r5. Meanwhile, the insert byte (insbl) instruction moves the byte from t into the correct byte position, also using the three low-order bits of the address in r3. The bis performs a logical OR operation that merges the byte into the correct position, and the store unaligned (stq_u) instruction stores the word back into s. The t and s pointers are incremented, the byte is checked for zero, and the sequence starts again if the byte is nonzero.
The basic operations performed by both architectures are rather similar. One difference is the combined floating-point multiply-add in the PowerPC. This instruction requires three floating-point register read ports. The 21064 has three such ports but uses them for stores so that a floating-point operate can be done simultaneously with a floating point store; this can't be done in the 601.
The Alpha architecture does not have an integer-divide instruction; it must be implemented in software. Leaving out integer divides, or doing them in clever ways to reduce hardware, seems to be fashionable in RISC architectures, however, iterative dividers are cheap, and one can expect that all the RISC architectures will eventually succumb to divide instructions (some already have).
The Alpha architecture has scaled integer adds and subtracts that multiply one of the operands by 4 or 8--one of the few Alpha features that seems non-RISCy. These instructions are useful for address arithmetic in which indices of word or doubleword arrays are held as element offsets, then automatically converted to byte-address values for address calculation using the scaled add/subtracts. The PowerPC has a richer set of indexing operations embedded in loads and stores as well as the update version of memory instructions.
We have just seen that the PowerPC 601 and Alpha 21064 represent two distinct design philosophies. The 601 implements an instruction set containing more powerful instructions. And, it uses an implementation that provides considerable flexibility to enhance detection and exploitation of parallelism by the hardware.
Of course, this results in more-complex hardware control. The Alpha 21064 uses a very streamlined instruction set and implementation. While not appearing as clever as the 601, the simplicity of the implementation contributes to a very fast clock rate--much faster than any other commercial microprocessor.
As a final note, follow-on processors from DEC and the PowerPC consortium, the Alpha 21164 and PowerPC 604, continue the differing design philosophies. The 21164 can issue more instructions per cycle than the 21064, but its pipelines are still relatively simple, and it has a very fast clock.
The 604, on the other hand, is even more aggressive than the 601 when it comes to providing hardware mechanisms for increasing parallelism--although, as one would expect, this comes at the expense of hardware control complexity.
Table 1: Architectural characteristics.
PowerPC 601 Alpha 21064
Basic architecture load/store load/store
Instruction length 32-bit 32-bit
Byte/halfword load/store yes no
Condition codes yes no
Conditional moves no yes
Integer registers 32 32
Integer-register size 32/64 bit 64 bit
Floating-point registers 32 32
Floating-register size 64 bit 64 bit
Floating-point format IEEE 32-bit, 64-bit IEEE, VAX 32-bit, 64-bit
Virtual address 52-80 bit 43-64 bit
32/64-mode bit yes no
Segmentation yes no
Page size 4 KB implementation specific
Table 2: Implementation characteristics.
PowerPC 601 Alpha 21064
Technology 0.6-micron CMOS 0.75-micron CMOS
Levels of metal 4 3
Die size 1.09 cm square 2.33 cm square
Transistor count 2.8 million 1.68 million
Total cache
(instructions + data) 32 KB 16 KB
Package 304-pin QFP 431-pin PGA
Clock frequency 50 MHz (initially) 150 to 200 MHz
Power dissipation 9 watts @ 50 MHz 30 watts @ 200 MHz
Table 3: Instruction dispatch rules; (a) In the 601, three mutually compatible instructions (marked with X) may issue simultaneously; (b) in the 21064, two compatible instructions may issue simultaneously. Integer branches depend on an integer register, and floating branches depend on a floating register.
Table 4: Register file ports.
Integer Registers Floating Registers
Read Ports Write Ports Read Ports Write Ports
PowerPC 601 3 2 3 2
Alpha 21064 4 2 3 2
Table 5: Branch penalties.
Alpha 21064 PowerPC 601
Distance Correct Incorrect Correct Incorrect
0 0-1 4 0 2/1
1 0-1 4 0 1/0
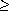 2 0-1 4 0 0
2 0-1 4 0 0
Table 6: Prediction methods versus branch type.
Conditional Branches Loop-closing Subroutine
(non-loop-closing) Branches Returns
PowerPC 601 Static prediction Always zero-cycle Always zero-cycle
Alpha 21064 Dynamic prediction Dynamic prediction Stack prediction
Example 1: Alpha 21064 pipelined processing example. (a) C code; (b) assembly code.
(a)
double x[512], y[512];for (k = 0; k < 512; k++)
x[k] = (r*x[k] + t*y[k]);
(b)
# r1 points to x
# r2 points to y
# r6 points to the end y
# fp2 contains t
# fp4 contains r
# r5 contains the constant 1
LOOP: ldt fp3 = y(r2,0) # load floating double
ldt fp1 = x(r1,0) # load floating double
mult fp3 = fp3,fp2 # floating multiply double t*y
addq r2 = r2,8 # bump y pointer
mult fp1 = fp1,fp4 # floating multiply double, r*x
subq r4 = r2,r6 # subtract y end from current pointer
addt fp1 = fp3,fp1 # floating add double, r*x+t*z
stt x(r1,0) = fp1 # store floating double to x(k)
addq r1 = r1,8 # bump x pointer
bne r4,LOOP # branch on r4 ne 0
Example 2: 21064 pipeline flow for loop example.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
ldt fp3=y(r2.0) F S D I A B W
ldt fp1=X(r1.0) F . S D I A B W
mult fp3=fp3.fp2 F S D . I F G H K I W
addq r2=r2.8 F S D . I A B W
mult fp1=fp1.fp4 F S . D I F G H J K W
subq r4=r2.r6 F S . D I A B W
addt fp1=fp3.fp1 F. S D . . . . . I F G H J K W
stt x(r1.0)=fp1 F. S D . . . . . . . . . I A B W
addq r1=r1.8 F S . . . . . . . . . D I A B W
bne r4.loop F S . . . . . . . . . D I A . .
ldt fp3=y(r2.0) F . . . . . . . . S D I A B
ldt fp1=x(r1.0) F . . . . . . . . . S D I A
Example 3: Example loop, unrolled for the Alpha 21064.
Issue time
LOOP: ldt fp3 = y(r2,0) # load y[k] 0
ldt fp1 = x(r1,0) # load x[k] 1
ldt fp7 = y(r2,8) # load y[k+1] 2
ldt fp5 = x(r1,8) # load x[k+1] 3
mult fp3 = fp3,fp2 # t*y[k] 4
ldt fp11 = y(r2,16) # load y[k+2] 4
mult fp1 = fp1,fp4 # r*x[k] 5
ldt fp9 = x(r1,16) # load x[k+2] 5
mult fp7 = fp7,fp2 # t*y[k+1] 6
ldt fp15 = y(r2,24) # load y[k+3] 6
mult fp5 = fp5,fp4 # r*x[k+1] 7
ldt fp13 = x(r1,24) # load x[k+3] 7
mult fp11 = fp11,fp2 # t*y[k+2] 8
addq r2 = r2,32 # bump y pointer 8
mult fp9 = fp9,fp4 # r*x[k+2] 9
subq r4 = r2,r6 # remaining y size 9
mult fp15 = fp15,fp2 # t*y[k+3] 10
mult fp13 = fp13,fp4 # r*x[k+3] 11
addt fp1 = fp3,fp1 # r*x[k]+t*y[k] 12
addt fp5 = fp7,fp5 # r*x[k+1]+t*y[k+1] 13
addt fp9 = fp11,fp9 # r*x[k+2]+t*y[k+2] 15
stt x(r1,0) = fp1 # store x[k] 16
addt fp13= fp15,fp13 # r*x[k+3]+t*y[k+3] 17
stt x(r1,8) = fp5 # store x[k+1] 17
stt x(r1,16) = fp9 # store x[k+2] 19
stt x(r1,24) = fp13 # store x[k+3] 21
addq r1 = r1,32 # bump x pointer 22
bne r4,LOOP # next loop 22
LOOP: ldt fp3 = y(r2,0) # next iteration 23
Example 4: Example loop, unrolled for the PowerPC 601. FXU instructions are dispatched and decoded in the same clock cycle.
Instr. FXU FPU BU
fetch decode decode exec.
time time time time
# CTR = 128 (loop count/4)
LOOP: lfs fp0 = y(r3,2052) # load y[k] 0 1
lfs fp4 = y(r3,2056) # load y[k+1] 0 2
lfs fp6 = y(r3,2060) # load y[k+2] 0 3
fmuls fp0 = fp0,fp1 # t*y[k] 0 4
lfs fp8 = y(r3,2064) # load y[k+3] 0 4
fmuls fp4 = fp4,fp1 # t*y[k+1] 0 5
lfs fp2 = x(r3,4) # load x[k] 0 5
fmuls fp6 = fp6,fp1 # t*y[k+2] 0 6
lfs fp5 = x(r3,8) # load x[k+1] 2 6
fmuls fp8 = fp8,fp1 # t*y[k+3] 2 7
lfs fp7 = x(r3,12) # load x[k+2] 9 10
fmadds fp0 = fp0,fp2,fp3 # r*x[k] + t*y[k] 9 11
lfs fp9 = x(r3,16) # load x[k+3] 9 11
fmadds fp4 = fp4,fp5,fp3 # r*x[k+1] + t*y[k+1] 9 12
fmadds fp6 = fp6,fp7,fp3 # r*x[k+2] + t*y[k+2] 9 13
fmadds fp8 = fp8,fp9,fp3 # r*x[k+3] + t*y[k+3] 9 14
stfs x(r3+4) = fp0 # store x[k] 10 14 15
stfs x(r3+8) = fp4 # store x[k+1] 10 15 16
stfs x(r3+12) = fp6 # store x[k+2] 10 16 17
stfsu x(r3=r3+16) = fp8 # store x[k+3] 10 17 18
bc LOOP,CTR$\neq$0 # dec CTR, branch if
CTR is not equal to 0 11 15
LOOP: lfs fp0 = y(r3,2052) # load y[k] 20 21
Example 5: Alpha 21064 conditional-move example. (a) C code; (b) assembly code with conditional branch; (c) assembly code with conditional move.
(a)
if (a == 1) c = b 2; else c = b 4;
(b) Issue time
# initially, assume
# r1 contains b,
# r7 points to a,
# r8 points to c.
ldl r2 = a(r7,0) # load a from memory 0
cmpeq r5 = r2,1 # test a 3
beq r5,SHFT2 # branch if a==1 4
# assume taken
sll & r3 = r1,4 # shift b 4
br & STORE # branch uncond &
SHFT2: sll & r4 = r1,2 # shift b 2
STORE: stl & r3 = c(r8,0) # store c & 6
(c) Issue time
# initially, assume
# r1 contains b,
# r7 points to a,
# r8 points to c.
ldl & r2 = a(r7,0) # load a from memory 0
sll & r3 = r1,4 # shift b 4 1
sll & r4 = r1,2 # shift b 2 2
cmpeq & r5 = r2,1 # test a 3
cmov & r3 = r4,r5 # conditional move to c 4
stl & r3 = c(r8,0) # store c 4
Example 7: Alpha 21064 strcpy function (null-terminated strings).
# A string is copied from t to s
# r4 points to t
# r3 points to s
LOOP: ldq_u r1 = t(r4,0) # load t, unaligned
extbl r2 = r1,r4 # extract byte from r1 to r2
ldq_u r5 = s(r3,0) # load s, unaligned
maskbl r5 = r5,r3 # zero corresponding byte in r5
insbl r6 = r2,r3 # insert byte into r6
bis r5 = r5,r6 # logical OR places byte in r5
stq_u s(r3,0) = r5 # store unaligned
addq r4 = r4,1 # bump the t pointer
addq r3 = r3,1 # bump the s pointer
bne r6,LOOP # branch if nonzero byte
Figure 1: Cache access paths. (a) Alpha 21064; (b) PowerPC 601.
Figure 2: Comparison of loop overlap in (a) 21064- and (b) PowerPC 601-like implementations.
Figure 3: Branch instructions. (a) Conditional branches; (b) unconditional branches.
Figure 4: Timing for conditional branches in the Alpha 21064. (a) Instruction flow for correct branch prediction; (b) instruction flow for incorrect branch prediction. (X means instruction is flushed as a result of branch misprediction.)
Figure 5: Format for PAL instructions used to define operating-system primitives.
Figure 6: Memory instruction format. (a) Load- and store-instruction format using register + displacement addressing. The displacement D is sign extended prior to addition. In Alpha, D is multiplied by 216 if OPCD = LDAH. RT is the destination register. (b) load- and store- instruction format using register + register (indexed) addressing. RT is the destination register.
Copyright © 1995, Dr. Dobb's Journal