Looking for an elegant solution led me to look at what Internet servers are doing to provide faster service to preferred customers. Most large-scale sites use multiple servers and load balancers or traffic managers to control the way the messages are distributed. I looked at hardware solutions by Cisco and F5 Networks, along with Microsoft software.
Balancing Load
Hardware traffic manager companies such as Cisco and F5 Networks use hardware to redirect user requests to a farm of servers based on server availability, IP address, or port number. All traffic is routed to the load balancer, then requests are fanned out to servers based on the running algorithm. Microsoft includes a software balancer called "Network Load Balancing" (NLB) in its Advanced Server architecture. The tool utilizes a virtual IP address for a cluster of servers to distribute incoming requests according to server availability. One of its downsides is that the cluster must consist entirely of Windows 2000 machines.
The reason for load balancers (or traffic managers) is to keep servers available for every user and fulfill their requests as quickly as possible. High availability is the key. Among the popular algorithms in use today are server availability, IP address, port number, and HTTP header.
- Server availability is based on keeping servers busy. If one server is busy, find another that has available processor power left. The traffic manager does not care what type of request it is or who sent it. The manager does have to be smart enough to recognize a transaction and maintain the association of the transaction to the server until completed. This method makes sure you get maximum output from your servers without regard to the content.
- IP address traffic management is typically used where data is located in several locations — mirror sites. A client's IP address is automatically checked to see which server farm is closest in proximity to the client. The request is then routed to that location and filled from there.
- Port number algorithms are more for traffic routing than load balancing. Every TCP packet has a port associated with its payload. The ports determine the handler for the packet. Port 80 are HTTP requests, port 81 are the responses. E-mail, FTP, HTTP, and DCOM all have unique port numbers. With port number switching, e-mail accounts are handled on one machine, HTTP on another, and FTP on yet another. This lets databases and files associated with each type of request be handled by machines dedicated to that task.
- HTTP header algorithms look into the request itself. The F5 Networks BIG/IP uses several techniques to improve service either with the cookie header, client source address, or URI to pick out customers who have bought from them before and provide them better service than unknown users or those just surfing through your site. This method gives the best service to those identified as preferred clients; the cost is processing time to parse the HTTP headers. Some implementations of this algorithm only look at the small fraction of the header to speed the parsing.
Predicting Normal Usage Patterns
Looking back to some work I did for the Navy, I knew I could model the system using Poisson Probability and Little's Theorem. The only difference here is that the data did not necessarily come in randomly over an entire day. There were two distinct spikes in the data — one at the start of the workday and another at the end. Poisson utilizes the average rate of arrival. I needed a method to get a better fix on the average than just taking the total hits for the day and calculating the average number per second.
I started by defining a data set. I had access to data from some web sites to use for comparison. By inspecting the data, I contend that I can use a Gaussian curve to model the number of users accessing the system during peak periods. Going back to my original requirement for the lighting system, employees entering a building should also follow this basic curve. Even if everyone arrived for work at exactly 8:00 am, the act of parking, entering the building, taking an elevator, and turning on each computer will tend to level out the arrival rate into my system.
Defining the Data Set
I chose to use data from a site that would typically be handled by one server but the process is valid for larger systems as well. The site has 5000 regular users per day. Typically, the site has a single peak. Aside from the regulars, there are a number of hits from surfers, bots, and the like that reach the site.
Figure 1 is a graph of the site for a typical day. If you look at the basic shape, it wouldn't make much sense to use the average for the day if we want to determine the worst-case performance. However, from the solid line on the graph, it is easy to see why I chose a Gaussian curve as it fits the data set fairly closely.
Using Gaussian Curves to Predict Peak Load
Although the data set is in hours, I'm really interested in determining how many seconds my users must wait for the server to respond. What I want to calculate, therefore, is the number of hits per second at the peak of my curve.
For my lighting system, I can have a maximum of 4000 users, and those users may hit the system at the beginning and end of the day. So for analysis purposes, I can work on a single curve centered at either 8:00 am or 5:00 pm.
Figure 2 is the equation for a Gaussian curve. The symbol y defines the number of users at the particular time and  is the standard deviation. For those who haven't spent much time in statistics, one standard deviation represents the distance away from the center of the curve I have to move to contain 68 percent of the data set. By the time I move three standard deviations from the center, the curve contains 99.7 percent of the data set. The symbol
is the standard deviation. For those who haven't spent much time in statistics, one standard deviation represents the distance away from the center of the curve I have to move to contain 68 percent of the data set. By the time I move three standard deviations from the center, the curve contains 99.7 percent of the data set. The symbol 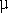 is the location of the mean or center of the curve. X is the number of units left or right of the mean. The unit curve is then multiplied by the number of requests contained by the curve to produce the final output. The curve lets you match the data set by adjusting the standard deviation. The final outcome that you are looking for, though, is the frequency of users per second at the mean.
is the location of the mean or center of the curve. X is the number of units left or right of the mean. The unit curve is then multiplied by the number of requests contained by the curve to produce the final output. The curve lets you match the data set by adjusting the standard deviation. The final outcome that you are looking for, though, is the frequency of users per second at the mean.
Poisson Probability to Pin Down Simultaneous Users
Poisson probability provides a way to calculate the probability of users simultaneously accessing the system. Looking at my lighting system, the absolute worst-case response of the system would occur if all 4000 users access the system at exactly the same time as the time clock decided to send 4000 commands to every light zone in the building. Wow! You'd need a big pipe to handle that. But in reality, there will be a relatively small number of users on the network at any given time.
Poisson is one of the methods for modeling the usage. The theory behind Poisson probability is that requests enter the system with an exponential probability that other users are entering the system at the same time. Using the average, I found that with Gaussian curves (1.33 users-per-second average) there is a high probability that 0, 1, 2, and 3 users will access the system simultaneously within my time period, but the probability of six or more users falls off drastically; see Figure 3.
Looking at Figure 4, is the average number of requests that can enter the system per unit time. This is the number derived from the Gaussian formula (Figure 2). The x term is the number of users simultaneously entering the system within the period. As I get to priority queues, I'll point out how I can handle most requests that fall outside the typical Poisson probability.
Now that the arrival rates (which models the user side of the system) have been defined, it's time to look into the server itself. You need to determine the effects of servicing the requests. This is where Little's Theorem enters the picture.
Calculating Turn-Around Time Using Little's Theorem
Little's Theorem states that you can define the throughput of a network as the ratio of the arrival rate over the service rate. If the system reaches a point where the ratio becomes greater than one, then I will exceed the capabilities of my system and either lose requests or have to queue them. I have finally made it to the point of interest. I can now define at what point my system fails. If I build in some queuing, the ratio can be exceeded as long as the queue is sufficiently large enough to accept the arriving requests, and the arrival rate eventually drops far enough to clear the queue. If the average ratio over time exceeds one, the system will fail — period.
Figure 5 determines the number of items in the queues and the amount of time a request will spend sitting in the queue before servicing.
This is where having the Poisson Probability becomes truly useful. I select my arrival rates based on the probability of multiple users accessing the system. It would have been possible to just use the average request rate I found from the Gaussian curves, but that would not give me the worst-case that I'm looking for. I can now predict both average throughput as well as the longest wait for any client.
Priority Queues
I needed to deal with time-clock events separately from the normal user traffic. I also had particular user commands that needed to be serviced before other users' commands. This is where the research on traffic managers becomes essential. You need to separate the incoming stream of commands, sorting by source and content. The source is either users or the time clock; the content is standard commands or privileged commands. By creating a set of prioritized queues, you can sort the incoming request stream into the queues and then remove the requests according to the priorities assigned to each queue.
A priority queue is a set of queues that provides access to the system based on which queue the data is placed into. The number of queues in the set determines the number of priority levels that you have. Figuring out the right number of queues depends on the application. With too many queues, the system is essentially just a switch where each type is sent to its own queue and there are more queues than types.
For this job, I used four queues. The highest priority queue supports the few special commands from users and system urgent action. Users are given the next queue, followed by the time clock. The last queue is used for status information. By giving priority to users, if the time clock is cycling through all 4000 zones and turns a user's lights off, users can issue a command that would be processed before any more lights are turned off by the time clock — a good thing.
You can begin to grasp what all this means by applying the aforementioned formulas to calculate the wait time for each user/type. The difference is that the wait time for each successively lower priority queue includes the wait for all the higher priority queues to dispatch first.
Balancing Load with Priority Queues
Getting back to my original problem of having 4000 users reaching the system and a time-clock event being triggered to the same 4000 light zones, compare how long users would have to wait with and without the priority queue. Assume that the profile is the same at 8:00 am as it is at 5:00 pm, so you can use a single curve to represent both time periods. You also know that you can service a command every 53 milliseconds, or about 19 commands per second.
When the time clock fires, there will be 4000 commands queued automatically. Without the priority queue, you'd have to wait 4000/19 seconds, or 3.5 minutes, before the first user could turn the lights back on. With the queues in place, you don't have to consider the time-clock events, as they will be processed only after any user commands. But you still want to know how long any user would have to wait before their command is processed.
With my 4000 users arriving around 8:00 am, I selected the standard deviation to be 20 minutes so that the majority of employees arrive within 20 minutes of 8:00 am. I could have chosen a tighter tolerance but this seemed to match my data set best. The maximum average rate of arrival at 1.330 users per second occurs right at 8:00 am.
Plugging the average rate into my Poisson Probability shows the probability of one user arriving without challenge is 35 percent, two users is 23 percent, and by six users the probability is down to 0.2 percent. A quick check that I'm going to be able to service my customers is that I can handle 19 users per second and the probability of getting swamped by 19 users simultaneously is 5×10-14 percent.
Table 1 shows the results of applying Little's Theorem and the approximate wait times for my users. As long as I stay below the magic 19 commands per second on average, the system will work well. For the most reasonable cases, users will wait less than 1/10th of a second.
Conclusion
By varying the parameters, you can easily play a few what-if scenarios quickly to see the effects on a system like this. This method can also be extended to multiple machines using a similar concept with the priority queue. The difference is that you do not need to accumulate the effects of the higher priority queue. Basically, each queue feeds one machine — effectively dividing the request rate by the number of servers. You don't have to use FIFO queues either. A priority queue can be used to redirect based on type, IP address, or whatever, distributing the requests as you see fit.
For More Information
Frost, V.S. and B. Melamed. "Traffic Modeling for Telecommunications Networks," IEEE Communications Magazine, March 1994.
DDJ